
The India Election Study aims to produce a high-resolution, spatially representative post-poll dataset. This dataset not only addresses questions of electoral outcomes but also explores broader issues related to socio-economic development, democracy, and welfare policies. The study accounts for the diversity of the Indian electorate by collecting samples from 200 randomly selected parliamentary constituencies across 20 states in India, encompassing over 1,600 polling booths and a sample size of 38,400 respondents.
For the sampling strategy
These states are all major states, representing 513 out of 543 parliamentary constituencies in the country. Among the 200 parliamentary constituencies (PCs) sampled, 33 were reserved for Scheduled Castes (SCs) and 16 for Scheduled Tribes (STs). A systematic random sampling with replacement technique was used to select 4 assembly constituencies (ACs) from each of these 200 PCs, resulting in a total of 800 ACs nationwide. In each of these 4 ACs, 2 polling booths (PBs) were randomly selected. From each of those polling booths, 24 respondents were randomly chosen to answer the final questions. Consequently, the survey encompasses approximately 1,600 polling booths and about 38,400 respondents across the country. The following diagram illustrates the sample design of the survey:
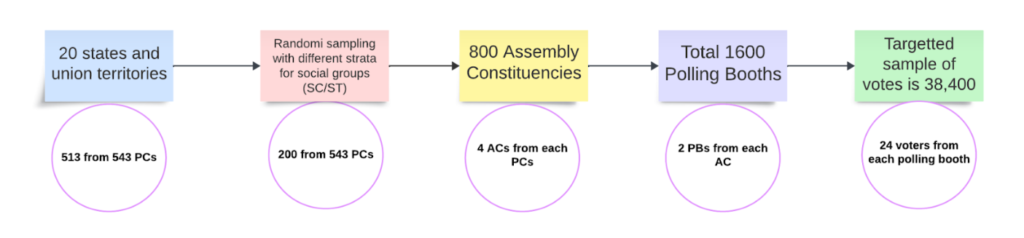
To conduct the survey, we randomly selected respondents from each polling booth (PB) and created a facepage for the enumerators to carry. This facepage included details of the parliamentary constituency (PC), assembly constituency (AC), and the PB, as well as information on the sampled and replacement respondents from each PB. This process ensured that enumerators reached the respondents selected randomly by the sample design, preventing any bias from personal selection. This unique sampling strategy, utilizing the electoral rolls for each PB, helps minimize post-estimation errors and allows for accurate tracking of respondents for future interactions.
The survey featured a comprehensive questionnaire covering various topics, including respondent backgrounds, electoral preferences, access to welfare schemes, preferences related to political leadership and governance, as well as questions on citizenship and media usage. We developed an extensive dictionary of state-specific and union government schemes tailored to each sampled state. Although this was a national survey, we invited our state teams to provide feedback and adjust questions, and allowed them to include a few state-specific questions, thus bridging regional and national concerns in the questionnaire. In addition to English, the final survey was translated into several local Indian languages. Enumerators received training in these languages to ensure successful execution and minimize non-sampling errors. A separate note on weights, models and other post estimation would be posted with the data.